



























Super-resolution GAN applies a deep network in combination with an adversary network to produce higher resolution images. Article from Medium Review written by Jonathan Hui on June, 2018. As shown above, SRGAN is more appealing to a human with more details compared with the similar design without GAN (SRResNet). During the training, A high-resolution image (HR) is downsampled to a low-resolution image (LR). A GAN generator upsamples LR images to super-resolution images (SR). We use a discriminator to distinguish the HR images and backpropagate the GAN loss to train the discriminator and the generator.

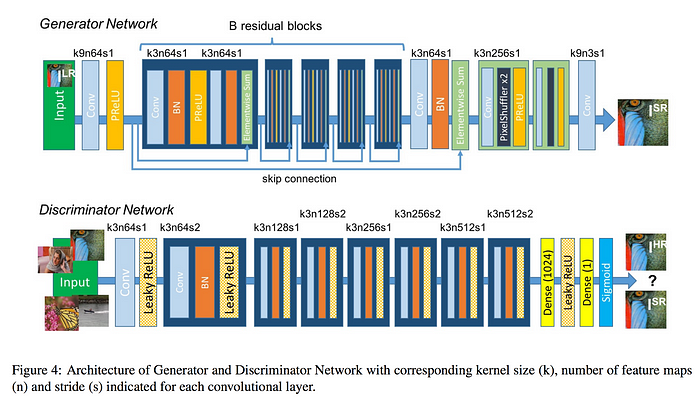
Below is the network design for the generator and the discriminator. It mostly composes of convolution layers, batch normalization and parameterized ReLU (PRelU). The generator also implements skip connections similar to ResNet. The convolution layer with “k3n64s1” stands for 3×3 kernel filters outputting 64 channels with stride 1.

Loss function
The loss function for the generator composes of the content loss (reconstruction loss) and the adversarial loss.
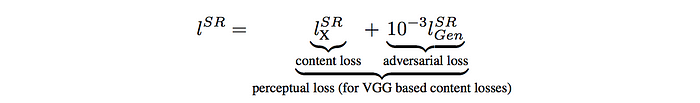
The adversarial loss is defined as:

We can compute the content loss pixel-wise using the mean square error (MSE) between the HR and SR images. Nevertheless, while it determines the distance mathematically, it is not necessarily more appealing to a human. SRGAN uses a perceptual loss measuring the MSE of features extracted by a VGG-19 network. For a specific layer within VGG-19, we want their features to be matched (Minimum MSE for features).

To train the discriminator, the loss function uses the typical GAN discriminator loss.

Social Media Development addict, Ashley Reyes is specialised on Emerging Techs & Crowdfunding Market. Ashley holds a Bachelor in Marketing and have 5+ years of experience in leader company as Marketing Intelligence Analyst . She is now Chief Community Officer at Athis News.






{kind=link}